Result Cache
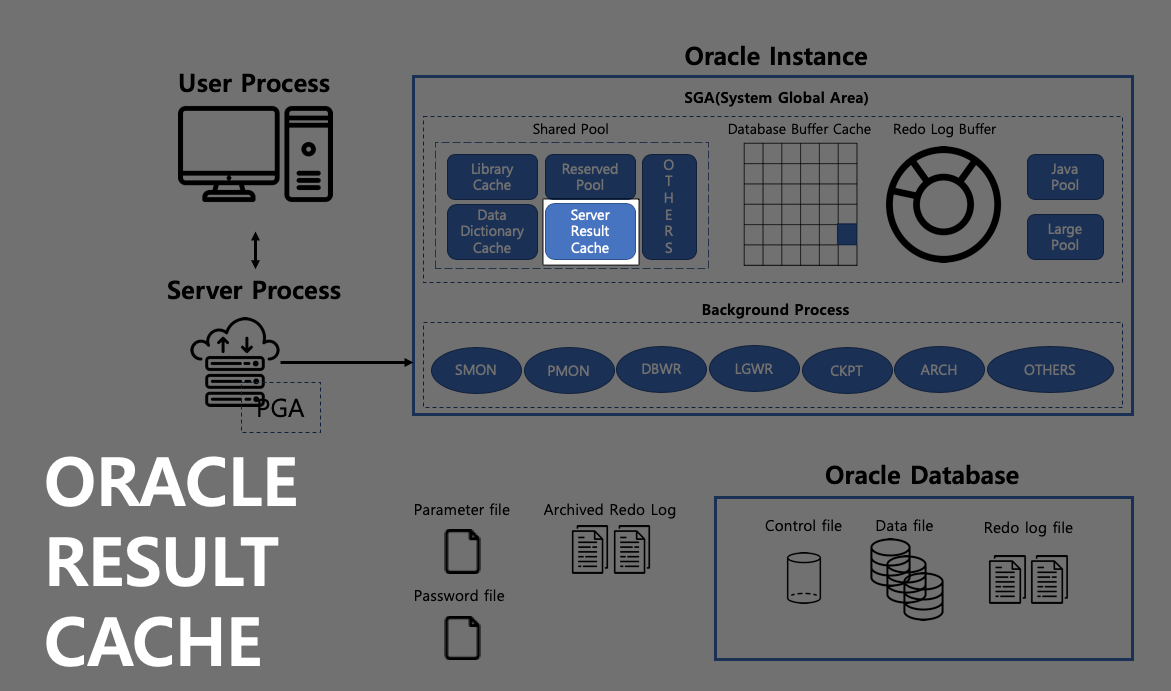
Result Cache는 Oracle 11g에서 처음 소개되었습니다. Result Cache는 사용자들의 대기 상황을 줄여줄 수 있는 대안으로 사용이 가능합니다.
어떤 사용자가 SQL 문장을 질의 했을때 Server Process가 가장 먼저하는 일은 Parse 작업을 통해 만들어진 실행계획으로 Database Buffer Cache에 필요한 데이터가 존재하는지 확인합니다. 한명의 사용자가 사용했을 때는 상관없지만, 다수의 사용자가 동시에 Database Buffer Cache를 접근하려고 할때 읽기 일관성을 유지하기 위해 Latch라는 메모리에 대한 Lock을 확보하여 Latch를 소유하고 있는 사용자만 해당 Block에 대한 작업 수행이 가능하여 다른 사용자가 대기하는 현상이 발생합니다.
Result Cache는 특정 SQL 질의에 대한 결과값 그 자체를 저장하여 같은 결과를 요청했을 때 Result Cache에서 바로 찾아 반환하여 대기하는 상황을 줄일 수 있습니다.
하지만, 사용에 있어서 코드표처럼 DML이 적은 데이터에 사용하는것이 효율적입니다. Result Cache에 Query에 대한 결과값 자체를 넣는 것인데 결과가 지속적으로 바뀐다면 효율이 오히려 떨어지는 상황이 발생할 수 있습니다.
Result Cache에 저장 가능한 경우
- 일반적인 SQL Query
- 특정 시점에 대한 Flashback Query
- Query 결과가 Read-consistent한 Snapshot
- View 또는 Inline view 형태의 Query Block
Result Cache에 저장하지 못하는 경우
- Dictionary 및 Temporary Table에 대한 SQL Query
- Sequence의 Curval/Nextval에 대한SQL Query
- current_date, current_timestamp, local_timestamp, userenv/sys_context(with non_constant variables)
- sys_guid, sysdate, sys_timestamp 등의 함수 호출이 포함된 SQL Query 문장
- Non-deterministic PL/SQL 함수를 호출하는 SQL Query 문장
Result Cache Default Sizing
- memory_target 사용 시 : memory_target * 0.0025(0.25%)
- sga_target 사용 시 : sga_target * 0.005(0.5%)
- shared_pool_size : shared_pool_size * 0.01(1%)
show parameter result_cache_max_size;
Result Cache Size를 명시적으로 지정하고자 할는 경우에는 result_size_max_size 파라미터를 지정하여 사용하면 됩니다. 0으로 지정시 disable되고 최대 값은 shared pool의 75%까지 설정이 가능합니다.
Result Cache 실습
Result Cache에 SQL Query에 대한 결과값을 넣어보는 실습을 하겠습니다.
show parameter result_cache_mode;
result_cache_max_size 파라미터가 0이 아닌것을 확인하여 disable되어 있지 않는 것은 위에서 확인해봤습니다. 다음은 result_cache_mode 파라미터를 확인하여 현재 활성화되어 있는 저장 방식을 확인합니다.
result cache_mode에는 두가지 방식이 있습니다.
MANUAL : /*+ result_cache */ 힌트를 사용하여 저장
FORCE : 모든 SQL 저장
Result Cache 통계 확인
SELECT
ID
,NAME
,VALUE
FROM V$RESULT_CACHE_STATISTICS;
여기서 봐야할 항목들은
Create Count Success : Result Cache에 생성된 오브젝트의 수
Find Count : Result Cache로부터 데이터를 읽은 수
만약 이 수치들이 0이 아닌경우 아래 명령어를 사용해서 Result Cache, Shared Pool 그리고 Buffer Cache를 모두 Flush 시켜줍니다.
SQL> EXECUTE DBMS_RESULT_CACHE.FLUSH;
SQL> ALTER SYSTEM FLUSH SHARED_POOL;
SQL> ALTER SYSTEM FLUSH BUFFER_CACHE;
Result Cache SQL문장 저장
현재 MANUAL 모드로 되어 있어 힌트를 사용하여 Result Cache에 데이터를 넣어보겠습니다.
실행계획을 확인하면서 보기 위해 autotrace는 on으로 설정하고 Query하겠습니다.
SET AUTOTRACE ON;SELECT /*+ RESULT_CACHE */
DEPTNO
,DNAME
FROM SCOTT.DEPT;
실행계획을 확인해보니 Result Cache에 저장되는 작업을 진행한 것을 확인할 수 있습니다.
SELECT
ID
,NAME
,VALUE
FROM V$RESULT_CACHE_STATISTICS;
다시 Result Cache의 통계를 확인해보니 Hash Chain Length가 하나 오르고 Create Count Success가 1로 바뀌어 하나의 Result Cache Object가 생성된 것을 확인할 수 있습니다. 하지만, 아직 Find Count는 0으로 한번도 Result Cache에서 데이터를 읽지 않았다는 것을 확인할 수 있습니다.
Result Cache SQL 문장 조회
이번에는 Result Cache의 문장을 조회하여 Find Count의 수가 올라가는 것을 확인해보겠습니다. 그전에 힌트를 제외하고 그냥 질의했을때 어떤 결과가 발생하는지 확인하겠습니다.
SELECT
DEPTNO
,DNAME
FROM SCOTT.DEPT;
힌트를 제외하고 조회했을때 일반적인 Table Full Scan을 통해서 실행한것을 확인할 수 있습니다.
SELECT
ID
,NAME
,VALUE
FROM V$RESULT_CACHE_STATISTICS;
결과를 확인해보니 Result Cache를 통해서 결과를 확인하지 않아 Find Count가 오르지 않은 것을 확인할 수 있습니다. 그럼 다시 힌트를 사용해서 조회를 해보겠습니다.
SELECT /*+ RESULT_CACHE */
DEPTNO
,DNAME
FROM SCOTT.DEPT;
SELECT
ID
,NAME
,VALUE
FROM V$RESULT_CACHE_STATISTICS;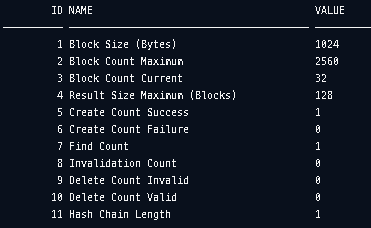
한번 더 힌트를 사용해서 조회를 해보니 Find Count가 오른것을 확인할 수 있습니다.
Force Mode
이번에는 Force Mode로 변경하여 모든 Query가 Result Cache로 들어가는 것을 확인해보겠습니다.
ALTER SESSION SET RESULT_CACHE_MODE=FORCE;SHOW PARAMETER RESULT_CACHE_MODE;
힌트를 제외하고 다시 질의해보겠습니다.
SELECT
DEPTNO
,DNAME
FROM SCOTT.DEPT;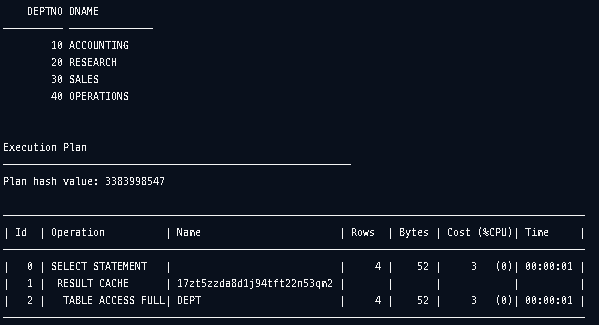
힌트를 제외하고 질의 했을 때도 Result Cache를 통해 결과를 얻는 것을 확인할 수 있었습니다.
SELECT
ID
,NAME
,VALUE
FROM V$RESULT_CACHE_STATISTICS;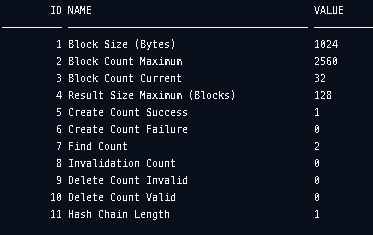
통계를 확인해보니 Find Count의 수가 1증가하여 2가된 것을 확인할 수 있습니다. FORCE MODE에서는 힌트를 사용하지 않고 모든 Query를 Result Cache에 넣는것을 확인할 수 있습니다.
SQL> SET AUTOTRACE OFF:
SQL> ALTER SESSION SET RESULT_CACHE_MODE=MANUAL;
Result Cache 정리
- 11g New Feature
- Query의 결과값 자체를 저장
- 사용자들이 대기하는 상황을 해소시킬 수 있는 대안
- DML이 거의 없는 데이터에서 사용하는 것이 효율적




댓글