Join

RDBMS에서는 정규화에 의해 연관된 데이터를 여러개의 테이블로 나누게 됩니다. 그래서 원하는 형식의 데이터를 받아오기 위해 여러개의 테이블을 연결하여 사용하는데 이를 Join을 통해서 할 수 있습니다. Join작업을 할때도 옵티마이저는 어떤 방식으로 조인을 할지 실행계획을 세우게 됩니다. 이번 글에서는 데이터베이스 내부적으로 어떻게 조인을 하는지 아래 3가지 방식에 대해서 알아보겠습니다.
- Nested Loop Join
- Sorted Merge Join
- Hash Join
실습환경
OS : Red Hat Enterprise Linux Server release 6.10
DB : Oracle 11.2.0.1
SID : orcl
user : jamong
테이블 구조
SYS@orcl> create table jamong.departments as select * from hr.departments;
SYS@orcl> create table jamong.employees as select * from hr.employees;
SYS@orcl> alter table jamong.departments add constraint pk_departments primary key(department_id);
SYS@orcl> alter table jamong.employees add constraint pk_employees primary key(employee_id);
JAMONG@orcl> create index employees_dept_idx on employees(department_id);
JAMONG@orcl> alter session set statistics_level=all;HR 계정의 기본 테이블의 데이터를 jamong 계정으로 이동하여 사용했고, 커서에 존재하는 실행계획을 수시로 확인하기 위해 statistics_level을 all로 설정했습니다. test table에 department_id에 대한 인덱스도 생성해줍니다.
xplan.sql
set linesize 150
set pagesize 100
select * from table(dbms_xplan.display_cursor(null,null,'allstats last cost'));start.sql
conn jamong/jamong
alter session set max_dump_file_size=unlimited;
alter session set events '10046 trace name context forever, level 12';end.sql
alter session set events '10046 trace name context off';
define _editor=vi
undefine trace
column trace_file new_value trace
SELECT value AS trace_file
FROM v$diag_info
WHERE name = 'Default Trace File';
!tkprof &trace output.trc sys=no
ed output.trc실행계획을 확인하기 위한 스크립트를 편리상 미리 만들어서 실습 진행하겠습니다. 실행 계획에 대한 상세 내용은 아래 글에서 확인할 수 있습니다.
[Oracle] 실행계획 확인 방법 XPLAN, AutoTrace, SQL Trace
실행계획 알고리즘 문제 풀때를 떠올려봅시다. 문제를 읽고 어떤 방식으로 풀어야 정확도와 효율성을 잡을 수 있을지 고민합니다. 완전탐색을 해야하는지, 이분탐으로 시간복잡도를 줄일 수 있
myjamong.tistory.com
1. Nested Loop Join
Nested Loop Join의 방식은 두개의 테이블의 행을 각각 모두 확인하여 조인하는 방법입니다. 표현하자면 중첩된 for문입니다. inner와 outer loop이 있듯이 조인에는 dirving과 driven 테이블이 있습니다. 실행계획에서 먼저 실행되는 테이블이 driving 테이블이고 나중에 실행되는 것이 driven 테이블입니다. 중첩된 for 문이라고 표현한 이유는 각각 테이블을 모두 읽고 확인하는 것이아니라 각 행별로 확인하기 때문에 행이 적은 테이블을 driving 테이블로 선정하는 것이 빠른결과를 얻을 수 있는 방법입니다. 또한 조인 컬럼에 인덱스가 있어야 테이블 전체를 탐색하지 않고 필요한 행에대해서만 탐색하여 효율적입니다.
예시
JAMONG@orcl> create table test as select * from employees;
JAMONG@orcl> insert into test select * from test;
JAMONG@orcl> insert into test select * from test;
JAMONG@orcl> insert into test select * from test;
JAMONG@orcl> insert into test select * from test;
JAMONG@orcl> insert into test select * from test;
JAMONG@orcl> insert into test select * from test;
JAMONG@orcl> insert into test select * from test;
JAMONG@orcl> insert into test select * from test;
JAMONG@orcl> insert into test select * from test;
JAMONG@orcl> insert into test select * from test;
JAMONG@orcl> insert into test select * from test;
JAMONG@orcl> insert into test select * from test;
JAMONG@orcl> insert into test select * from test;
JAMONG@orcl> create index test_dept_idx on test(department_id);성능의 확연한 차이를 확인하기 위해 test테이블을 90만건 정도의 테이블로 생성했습니다. 27건의 데이터를 갖고 있는 departments 테이블과 조인해서 결과를 확인해볼것입니다.
JAMONG@orcl> @start
JAMONG@orcl>
select /*+ leading(e) use_nl(d) */ count(*)
from test e, departments d
where e.department_id = d.department_id;
JAMONG@orcl> @end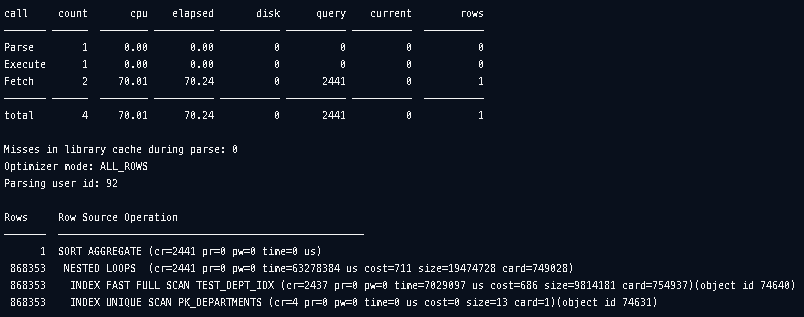
힌트를 사용해서 leading --> test 테이블을 driving 테이블로 설정하고 특별한 필터링없이 Nested Loop Join으로 실행하고 실행계획을 그림으로 그려봤을 때 위와 같습니다. 실행하는데 70초정도가 소요됬고 그럼 diving과 driven 테이블을 바꾸고 실행한 후 비교해보겠습니다.
JAMONG@orcl> @start
JAMONG@orcl>
select /*+ leading(d) use_nl(e) */ count(*)
from test e, departments d
where e.department_id = d.department_id;
JAMONG@orcl> @end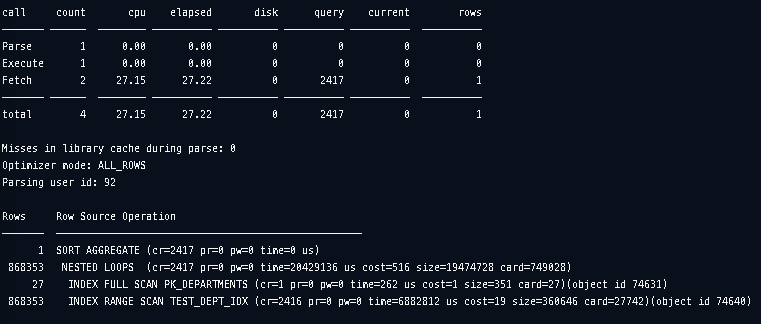
결과적으로 봤을때 driving 테이블이 departments일 때 실행 시간 27초로 71초보다 2배 이상 빠른 속도로 결과를 갖고 왔습니다. 실행계획을 봤을때 읽는 블록의 갯수는 크게 차이가 없습니다. 결과는 같으므로 반환되는 row의 갯수도 같은데 속도차이는 크게 납니다. count된 결과를 받는것으로 Table에 대한 Random Access 필요없이 인덱스만 갖고 결과를 받아왔습니다. 그러면 어떤 이유로 차이가 난걸까요? 바로 driving 테이블의 행의 갯수가 비교적 적다는 이유이고 Nested Loop Join이 레코드 하나씩 순차적으로 조인작업을 한다는 특징이 확실하게 보여집니다.
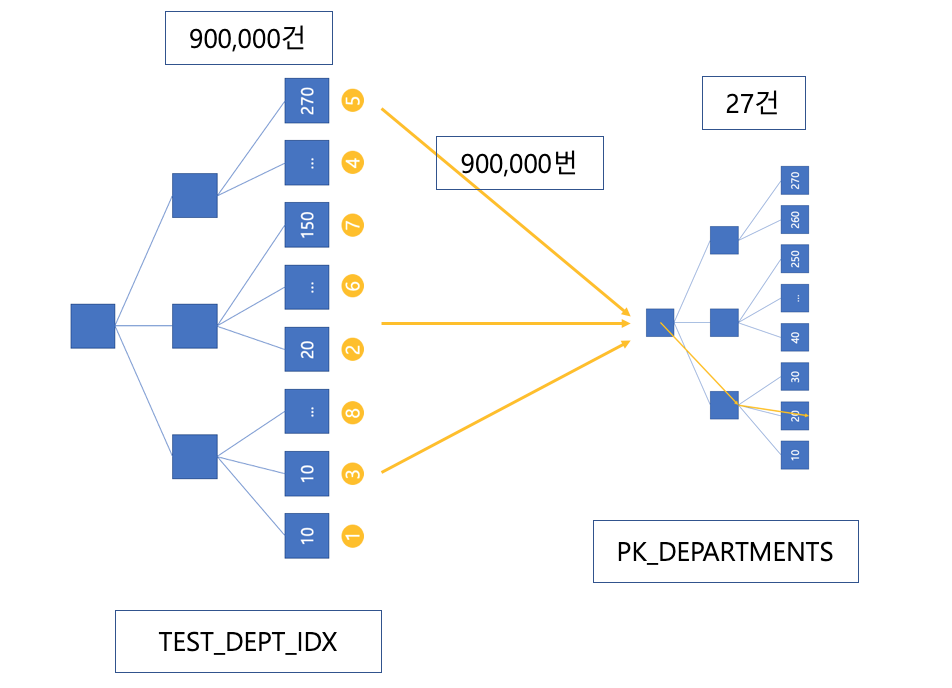
driving 테이블이 test일때의 상황을 먼저 보겠습니다. 레코드 하나씩 확인하기 때문에 먼저 TEST_DEPT_IDX를 각각 90만번 확인하면서 PK_DEPARTMENTS 인덱스를 Unique Scan으로 한번씩만 확인하여 결과를 받아옵니다. 그림으로 표현하자면 아래와같이 뻗어나가면서 데이터를 조인합니다.

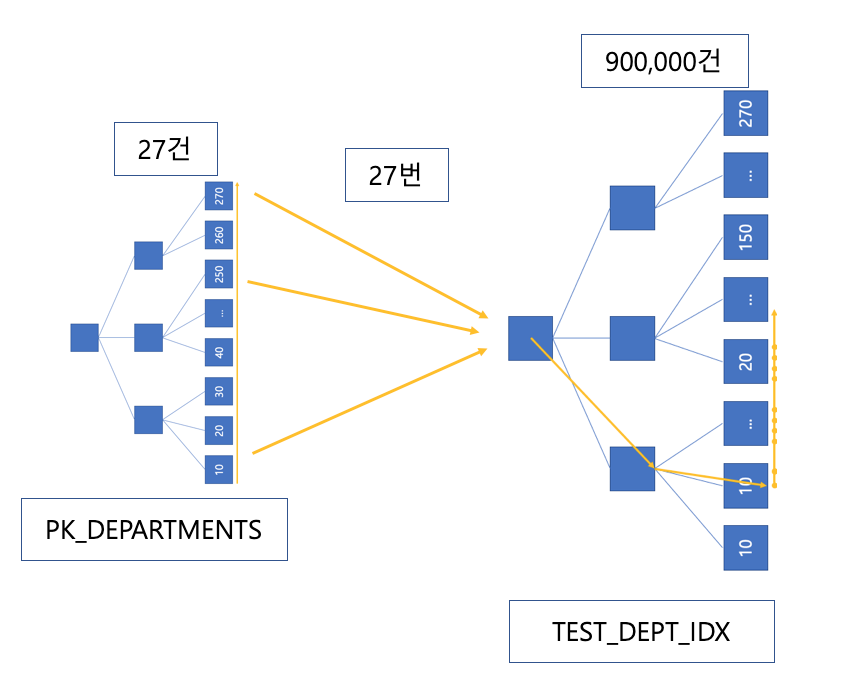
driving 테이블이 departments일때는 레코드를 PK_DEPARTMENTS에서 먼저 다 확인하고 각 레코드별로 Range Scan을 통해 TEST_DEPT_IDX를 탐색합니다. 아래와 같은 식으로 순회합니다.

그림으로만 봐도 확연하게 차이를 느낄수 있습니다. driving 테이블의 레코드가 적은 경우 driven 테이블에서 일일히 Root 블록을 거치는 일이 작기 때문에 훨씬 빠른 속도로 결과를 얻을 수 있습니다. 물론, 인덱스가 모두 없는 테이블의 경우에는 어떤 경우에든 모두 Full Table Scan을 하기 때문에 의미가 없습니다. 그럼 이번에는 count가 아닌 테이블의 결과를 출력하여 Random Access했을 때의 경우를 살펴보겠습니다.
e_lead.sql
select /*+ leading(e) use_nl(d) */
e.employee_id,
e.first_name,
e.salary,
d.department_id,
d.location_id
from test e, departments d
where e.department_id = d.department_id
and e.employee_id > 150
and d.location_id = 2700;d_lead.sql
select /*+ leading(d) use_nl(e) */
e.employee_id,
e.first_name,
e.salary,
d.department_id,
d.location_id
from test e, departments d
where e.department_id = d.department_id
and e.employee_id > 150
and d.location_id = 2700;결과 출력되는 내용이 많아서 script에 작성 후 termout 옵션을 끄고 실습진행하겠습니다.
JAMONG@orcl> set termout off
JAMONG@orcl> @start
JAMONG@orcl> @e_lead
JAMONG@orcl> set termout on
JAMONG@orcl> @end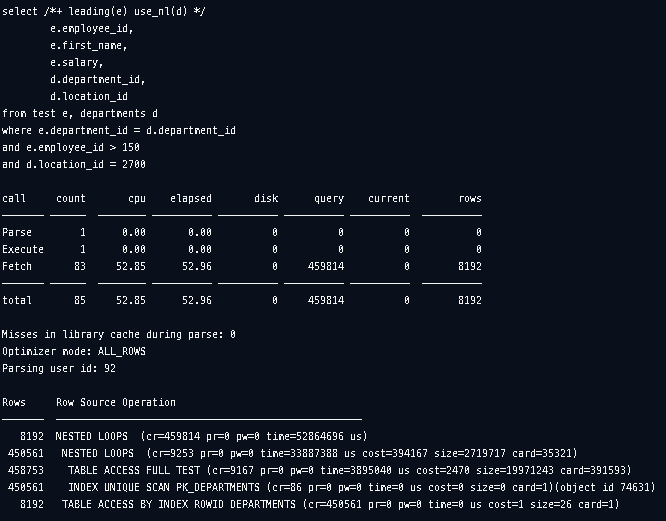
test Table이 Driving Table인 경우입니다. 우선 출력하는 데이터의 양이 많아 Test 테이블을 Full Table Scan을 통해 탐색을하면서 employee_id 가 150 이하인 레코드는 필터링한것으로 봅니다. 즉 90만건을 전부확인하면서 대략 45만건의 데이터가 필터링됩니다. 그다음 45만건에 대해서 PK_DEPARTMENTS 인덱스와 조인작업을합니다. 조인된 결과를 갖고 departments 테이블과 다시 조인하게 되는데 ROWID에 대한 조인으로 Access하면서 location_id가 2700인 데이터를 필터링합니다.
driving table에서 45만건의 데이터를 조인하는데 결과로 8000건정도의 데이터를 얻는 것은 읽은 데이터 중 상당한 양을 버리는 것으로 문제가 있는 것으로 판단할 수 있습니다.
JAMONG@orcl> set termout off
JAMONG@orcl> @start
JAMONG@orcl> @d_lead
JAMONG@orcl> set termout on
JAMONG@orcl> @end
이번에는 departments 테이블이 driving 테이블입니다. 가장 먼저 Departments Table을 Full Table Scan하면서 location_id가 2700인 레코드를 필터링해서 1건의 데이터를 얻습니다. 그다음 TEST_DEPT_IDX 인덱스를 탐색하는데 departments 테이블에서 하나의 레코드에 대해서만 확인하며 조인하면 됩니다. 그 이후 TEST 테이블 Access를 하면서 employee_id가 150 보다 높은 조건을 필터링하는데 공교롭게도 이전에 필터링된 결과가 모두 해당 조건을 만족하여 버리는 행 없이 모두 ROWID에 대해 조인 작업을 하게됩니다.
실행하는데 소요된 시간만 비교해보면 52초에서 1초로 줄일 수 있었습니다. 몇가지 조건을 처리하여 조인하기 이전에 driving 테이블에서 필터작업을 진행하여 driving table의 행을 줄여주면 확실한 성능차이를 확인할 수 있었습니다. 그만큰 Nested Loop Join에서는 driving, driven 테이블을 어떻게 지정하는지가 중요하고 인덱스에 의존적입니다.
특징
- driving 테이블 결정 후 driven 테이블에 반복적인 접근
- 한 레코드씩 순차적으로 접근
- 많은 양의 데이터 조인 시 Random Access 증가
- Random Access 위주의 조인 방식
- 소량의 데이터를 조인 시 사용
- 부분 범위 처리에 최적화
- 인덱스 구성 전량이 중요
2. Sorted Merge Join

Sorted Merge Join은 두개의 테이블을 조인 칼럼으로 정렬하여 조인하는 방법입니다. 정렬된 테이블로 조인하기 때문에 인덱스를 활용하는 효과와 비슷합니다. Sorted Merge Join은 Nested Loop Join의 조인과 수행 과정이 다르지 않습니다. 단, PGA 영역을 이용하여 정렬작업을 하기 때문에 래치 확득할 필요가 없어 Index를 통해 Table Access하는 것보다 빠릅니다. 이러 한 특성을 갖고 있어 조인되는 칼럼에 인덱스가 없는 경우에 유리할 수 있습니다.
인덱스가 없는 두테이블에 대해서 Nested Loop Join을 하는 경우 driving table의 각각 행에 대해 driven table을 Full Scan하기 때문에 인덱스에 많이 의존하게 됩니다. 반면, Sorted Merge Join은 인덱스가 없어도 조인칼럼을 기준으로 정렬한 후 inner table 조회시 outer table의 값에 대해서만 조인하면 되기 때문에 인덱스가 없는 경우에 사용될 수 있고 이러한 정렬 작업에 대한 부하를 감수한다면 Nested Loop Join 보다 유리할 수 있습니다.
예시
Sorted Merge Join은 Hash join의 등장으로 사용이 많이 줄어들었습니다. 하지만 여전히 Sorted Merge Join을 사용하는게 유리한 경우가 있습니다. Outer 집합이 정렬되어 있는 경우와 Non equi join을 사용하는 경우 입니다.
첫번째는 Outer 집합이 정렬되어 있는 경우를 살펴보겠습니다.
JAMONG@orcl>
select
e.employee_id,
e.first_name,
e.salary,
d.department_id,
d.location_id
from employees e, departments d
where e.department_id = d.department_id;
JAMONG@orcl> @xplan
만약 Outer Table을 index를 이용한 탐색을 한다면 Sort Merge Join 시 정렬 작업을 대체할 수 있습니다. 위의 쿼리에서도 Outer Table departments를 Index Full Scan에 의해서 Table Access를 한 후 employees 테이블을 읽어 sorting 작업을 합니다. 이후 merge 작업을 하고 결과를 반환합니다. 이와 같이 outer table에 인덱스로 정렬작업을 대체해서 Sorted Merge Join을 사용할 수 있습니다.
인덱스를 사용하지 않고 이미 Outer Table이 정렬되어 있는 경우 조인을 위해 다시 정렬작업을 하지 않아도 되므로 Sorted Merge Join이 유리할 수 있습니다.
JAMONG@orcl>
select
d.department_name,
e.sal_avg
from
departments d,
(
select
department_id,
avg(salary) as sal_avg
from employees
group by department_id
order by department_id
) e
where e.department_id = d.department_id;
JAMONG@orcl> @xplan
각 부서를 부서의 평균 급여와 함께 출력하는 쿼리입니다. e 집합에 대해서 grouping하고 조인되는 칼럼으로 미리 정렬되어 있기 때문에 옵티마이저는 Sorted Merge Join으로 실행계획은 선택합니다.
JAMONG@orcl> create table salgrade(grade number,losal number,hisal number);
JAMONG@orcl> insert into salgrade values(1,0,4000);
JAMONG@orcl> insert into salgrade values(2,4001,8000);
JAMONG@orcl> insert into salgrade values(3,8001,12000);
JAMONG@orcl> insert into salgrade values(4,12001,16000);
JAMONG@orcl> insert into salgrade values(5,16001,50000);
JAMONG@orcl>
select
e.employee_id,
e.salary,
s.grade
from employees e, salgrade s
where e.salary between s.losal and s.hisal;
JAMONG@orcl> @xplan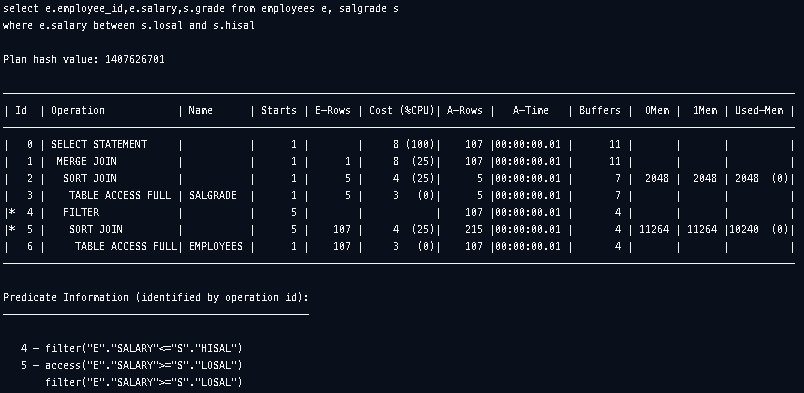
급여별 등급을 나누는 테이블 salgrade를 생성하고 직원의 등급을 같이 출력하는 non equi join 쿼리를 실행해봤습니다. 양 테이블을 정렬하고 sort merge join을 옵티마이저가 택한것을 확인할 수 있습니다. 조인 조건에 맞는 범위에 대해 필터한 Inner table을 각각 졍렬된 상태로 Outer Table로부터 순차적으로 읽어 non equi join을 하는데 유리할 수 있습니다.
특징
- 조인 칼럼으로 저렬 후 조인 수행
- 실시작으로 인덱스를 생성하는 것과 비슷
- 정렬할 데이터가 많은 경우 부담이 가장 큰 조인 방법
- 두 테이블 개별적으로 읽고 조인
- Outer Table에 인덱스가 있을 경우 사용
- Outer Table이 정렬되어 있을 때 사용
- Non equi join 사용 시 사용
3. Hash Join
Hash Join은 Hash Table을 생성하여 Hash Function에 의한 탐색을 하여 조인합니다. 주로 대용량의 데이터를 사용할 때 사용되며 일반적으로 Nested Loop Join이나 Sorted Merge Join보다 빠르다고합니다. 알고리즘에서 시간 복잡도의 개념으로 봤을 때도 Hash Function을 사용하게 되면 O(1)의 시간 복잡도를 갖게되니까 빠를수 밖에 없는 것 같습니다. 하지만, 해시 충돌을 방지나 해시 체인의 크기가 커지는 것을 막기 위해 중복되는 데이터가 적은 경우에 사용되어하고 Hash Table을 생성하는데 Hash Area에 충분히 담길 정도로 데이터 양이 작아야합니다.
예시
JAMONG@orcl>
select /*+use_hash(d,e)*/
d.department_id,
d.department_name,
e.last_name,
e.salary
from departments d, employees e
where d.department_id = e.department_id;
JAMONG@orcl> @xplan
힌트를 사용해서 결과를 확인해봤습니다. Hash Join 수행시 메모리를 사용하여 Hash Table을 사용하는 것을 확인할 수 있습니다. Hash Join이 빠르다고 하는 이유 또한 PGA영역을 사용하여 Latch를 확득 과정이 없어 빠르게 결과를 얻을 수 있습니다.
특징
- 두 집합 중 크기가 작은 집합을 Outer Table로 결정
- Outer Table이 Hash Area에 담길 정도로 충분히 작을 때 사용
- Outer Table의 해시 키 칼럼에 중복값이 거의 없을 때 사용
- 대량의 데이터를 조인시 사용
- 소량의 데이터를 조인할 때 오히려 불필요한 I/O가 증가할 수 있음
- Equi Join에서만 가능
- 조인 칼럼에 적당한 인덱스가 없는데 Nested Loop Join이 비효율 적일 때 사용
- Nested Loop Join에서 조인 칼럼에 인덱스가 있더라도 Random Access 부하가 심할 때 사용
- Sort Merge Join 사용 시 두개의 집합이 너무 컷 정렬하는데 부하가 심할 때 사용



댓글