
Python 3.9.5 버전을 사용했습니다.
데이터 구조(Data Structure)란?
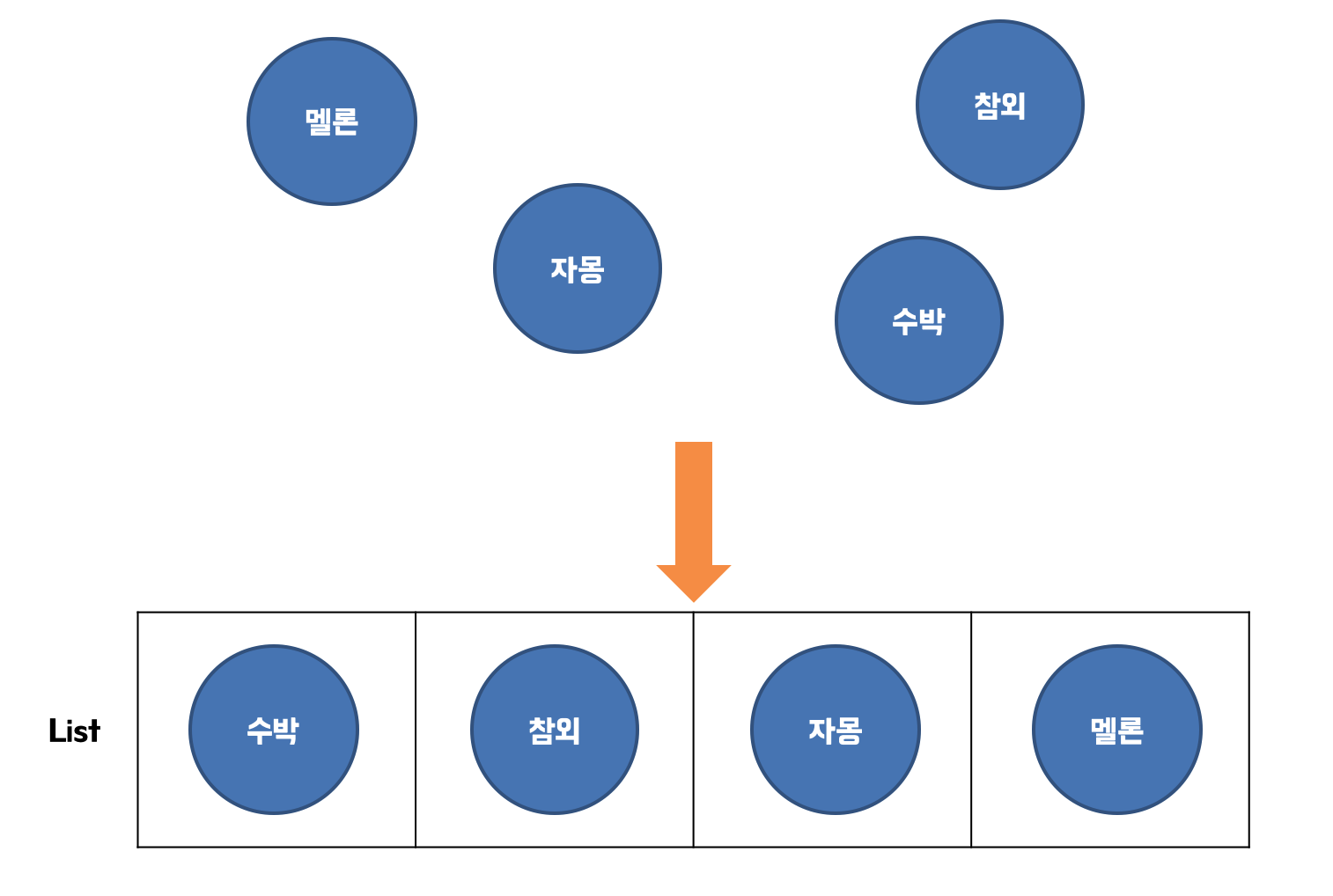
데이터 구조는 여러 데이터를 효율적으로 저장하기 위해 하나의 집합으로 데이터를 저장하는 구조(structure) 입니다. 이전에 변수에 숫자나 문자 형태의 데이터 타입을 저장했었는데... 과일들의 집합 처럼 연관된 데이터를 모두 각각 다른 변수로 선언을 해줘야할까요?
# 각각 변수로 선언
fruit1 = '수박'
fruit2 = '참외'
fruit3 = '자몽'
fruit4 = '멜론'
# 데이터 구조인 리스트를 사용해서 선언
fruits = ['수박', '참외', '자몽', '멜론']위의 이미지를 코드화한 내용입니다. 연관된 데이터를 각각 변수로 만들지 않고 데이터 구조 중 하나인 list를 만들어서 하나의 변수에서 관리하면 편리하게 사용할 수 있습니다.
Python의 데이터 구조
Python에서 제공해주는 데이터 구조는 아래와 같습니다.
- List
- Tuple
- Set
- Dictionary
이번 글에서는 위 4가지 데이터 구조에 대해서 알아보겠습니다.
List (리스트)
다른 언어에서는 Array(배열)라고 합니다. 수학적 의미에서의 배열과 같이 생각하시면 될 것 같고 리스트는 데이터를 순차적으로 저장해서 사용할 수 있는 데이터 구조입니다.
List 읽기
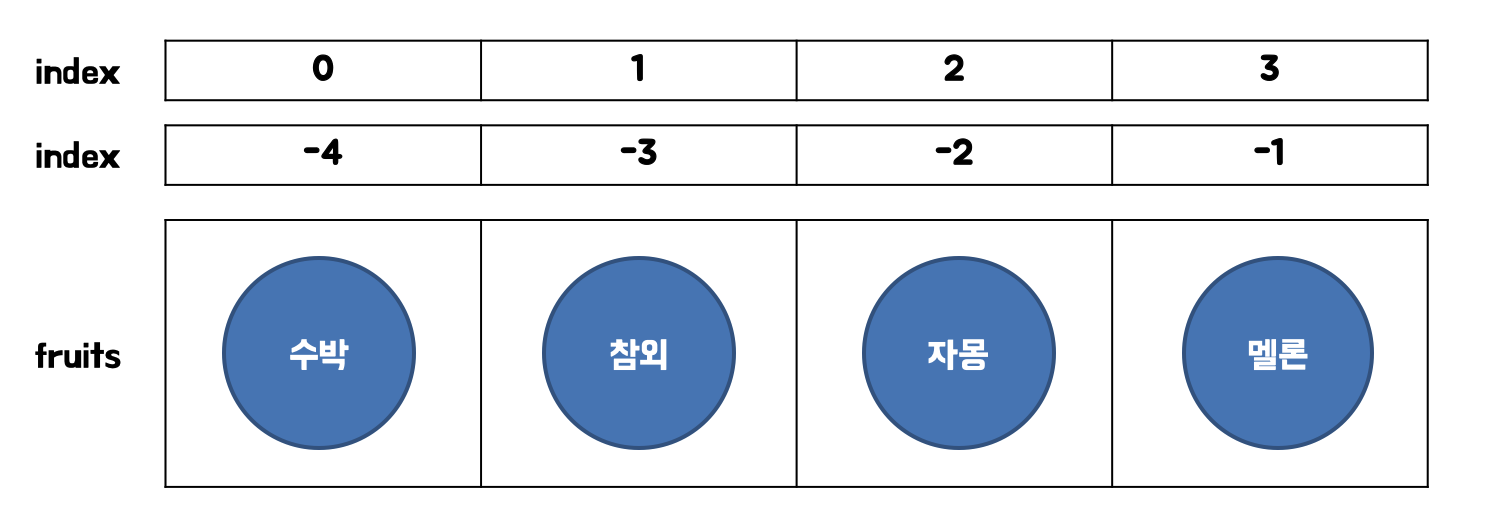
# 과일을 담은 리스트
fruits = ['수박', '참외', '자몽', '멜론']
# len 함수를 통해 리스트의 길이를 확인할 수 있습니다.
print(len(fruits)) # 4
print(fruits[0]) # 수박
print(fruits[1]) # 참외
print(fruits[2]) # 자몽
print(fruits[3]) # 멜론
print(fruits[4]) # IndexError: list index out of range
print(fruits[-1]) # 멜론
print(fruits[-2]) # 자몽
print(fruits[-3]) # 참외
print(fruits[-4]) # 수박
print(fruits[-5]) # IndexError: list index out of range리스트 타입으로 정의된 데이터는 순차적으로 데이터를 저장하고 대괄호([])에 인덱스를 넣어서 값을 호출 할 수 있습니다. 인덱스는 0부터 시작해서 값을 호출할 때 주의해야합니다. 리스트의 길이가 4인 경우 인덱스는 0 ~ 3까지이고 4를 넣어서 호출하는 경우 오류가 발생합니다.
Python에는 음수의 인덱스도 사용할 수 있습니다. 양수 인덱스와는 반대로 -1부터 시작하고 리스트의 끝에서부터 데이터를 읽습니다. 마찬가지로 리스트의 길이를 벗어나면 오류가 발생합니다.
List 데이터 내장된 함수로 제어
# 과일을 담은 리스트
fruits = ['수박', '참외', '자몽', '멜론']
# 리스트 끝에 추가
fruits.append('망고')
print(fruits) # ['수박', '참외', '자몽', '멜론', '망고']
# 리스트 특정 위치에 삽입 --> 지정한 인덱스에 값을 저장한다.
fruits.insert(2, '망고')
print(fruits) # ['수박', '참외', '망고', '자몽', '멜론', '망고']
# 리스트에서 값으로 제거(첫번 째 값 만 제거된다)
fruits.remove('망고')
print(fruits) # ['수박', '참외', '자몽', '멜론', '망고']
# 리스트에서 인덱스로 값 제거하고 반환한다
print(fruits.pop(4)) # 망고
print(fruits) # ['수박', '참외', '자몽', '멜론']
# 리스트 역순으로 재배치한다.
fruits.reverse()
print(fruits) # ['멜론', '자몽', '참외', '수박']
# 리스트의 모든 값을 제거한다.
fruits.clear()
print(fruits) # []리스트의 데이터를 내장되어 있는 함수로 제어할 수 있습니다. 각각 설명은 실습으로 대체하겠습니다.
Python Slicing 개념
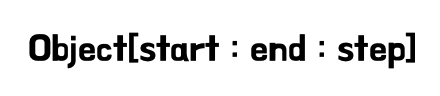
Python에는 List 처럼 연속적인 데이터를 갖는 객체들에 slicing이라는 강력한 기능을 사용할 수 있습니다. slicing은 자르다의 의미를 갖고 있는데... 말 그대로 범위를 지정해서 선택할 수 있는 기능 입니다.
start : slicing의 시작 위치 (해당 인덱스는 포함한다.)
end : sliceing의 끝 위치 (해당 인덱스는 포함하지 않는다.)
step : 폭 (인덱스의 차이)
# 과일을 담은 리스트
fruits = ['수박', '참외', '자몽', '멜론']
# 인덱스 2 전까지 범위로 한다.
print(fruits[:2]) # ['수박', '참외']
# 인덱스 2를 포함해서 끝까지 범위로 한다.
print(fruits[2:]) # ['자몽', '멜론']
# 인덱스 1부터 4 전까지 범위로 한다.
print(fruits[1:4]) # ['참외', '자몽', '멜론']
# 인덱스 0 부터 4 전까지 범위로 잡고 2개씩 건너 뛴다.
print(fruits[0:4:2]) # ['수박', '자몽']예제를 통해서 익힌다.
다른 언어를 사용해보셨으면 느끼시겠지만... 이런 문자열 관련제어는 Python이 문법적으로 정말 쉽게할 수 있습니다. Python에서 한줄이면 해결할 수 있는 것을 다른 언어에서는 4~5 줄 정도 작성해야합니다.
del 예약어
인덱스로 리스트의 값을 제거하는 방법으로 del 예약어를 사용하는 방법이 있습니다. 리스트의 pop 메소드와의 차이는 값을 반환해주지 않는 다는 점입니다. 그리고 slicing을 통해서 범위로 값을 삭제할 수 있습니다.
# 과일을 담은 리스트
fruits = ['수박', '참외', '자몽', '멜론']
# 인덱스 1의 값을 삭제한다.
del fruits[1]
print(fruits) # ['수박', '자몽', '멜론']
# 인덱스 1부터 3 전까지의 범위를 삭제한다.
del fruits[1:3]
print(fruits) # ['수박']
# 리스트의 모든 값을 삭제한다. --> clear함수와 동등합니다.
del fruits[:]
print(fruits) # []실습을 통해 확인한다.
List 타입 참조
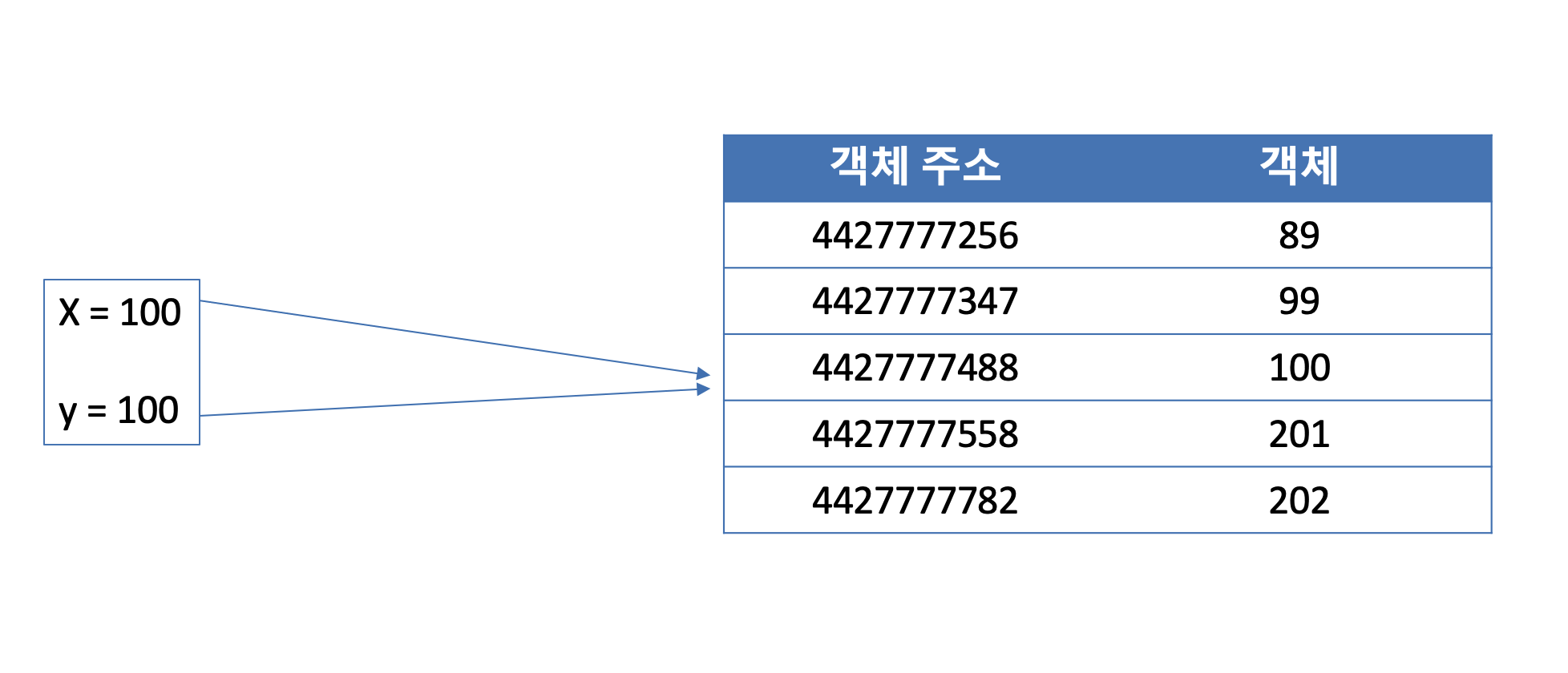
x = 100
print(id(x)) # 4427777488
y = 100
print(id(y)) # 4427777488
Python에서는 모든 것이 오브젝트로 되어 있다고 했습니다. 그래서 100이라는 객체를 두개의 변수가 바라보면 같은 객체를 바라봅니다. 리스트를 생성해서 사용할 때도 마찬가지만... 다만 조금 다르게 이해해야하는 부분이 있습니다.

x = [1, 2, 3]
print(id(x)) # 4330506944
y = [1, 2, 3]
print(id(y)) # 4330825600변수에 숫자형 데이터를 할당해줬을 때와 달리... 똑같은 데이터를 넣은 리스트를 각각 x와 y에 할당해 줬을 때... 둘은 같은 객체일까요? 정답은 다른 객체 입니다. 이는 Python에서 내부적으로 list 데이터 구조로 변수를 초기화해주면 무조건 메모리에 새롭게 객체를 할당하게끔 한 것이고 이렇게 해야하는 이유도 있습니다.
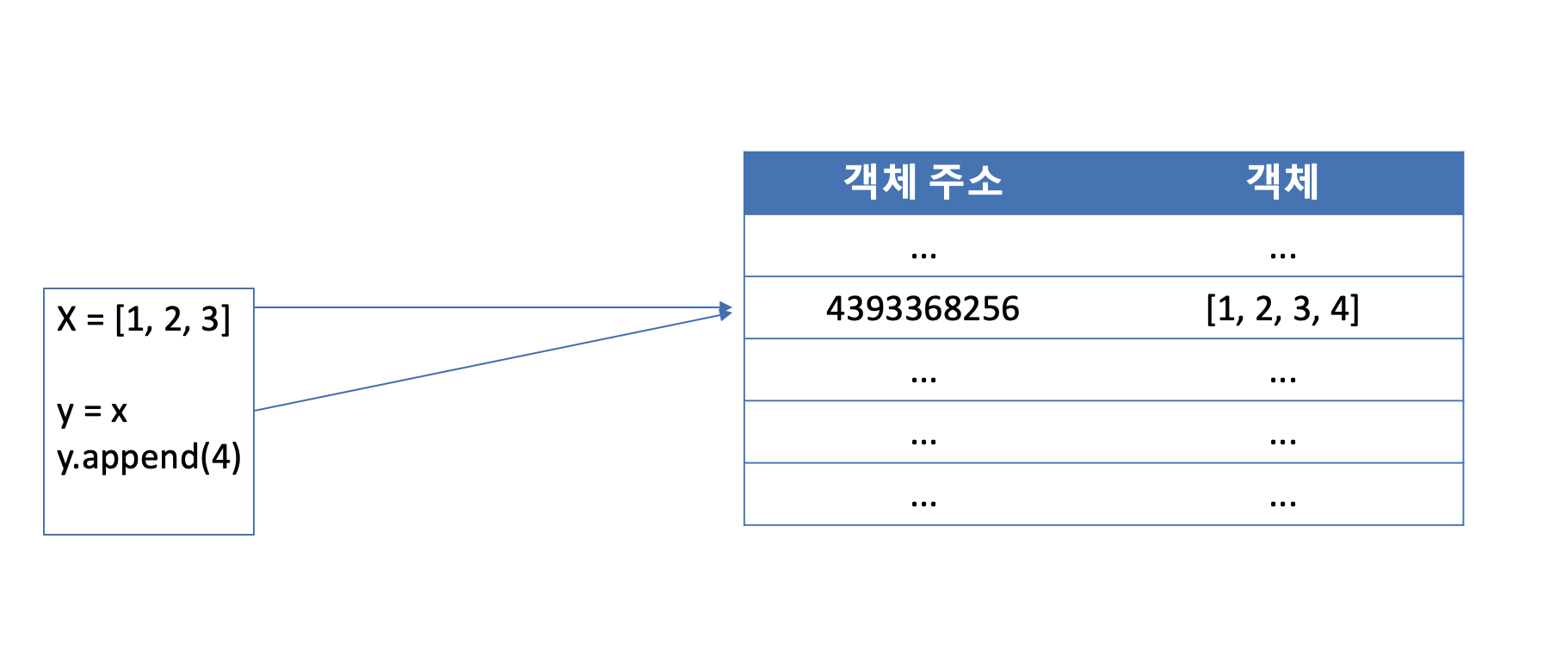
x = [1, 2, 3]
y = x
y.append(4)
print(x) # [1, 2, 3, 4]
print(y) # [1, 2, 3, 4]x라는 리스트를 초기화 시켜주고 y라는 변수에 x와 똑같은 값이 들어가는 리스트를 만들어 줬습니다. x와 y는 따로 데이터를 제어할 수 있도록 해야하는데... x와 y는 같은 객체를 바라보고 있기 때문에 y를 변경했는데 x도 변경된 리스트를 보여주고 있죠. 숫자형 데이터 타입처럼 만약 리스트의 값이 같을 때 같은 객체를 참조하면... 위와 같이 변경되면 안되는 데이터가 변경되버리는 문제가 발생합니다. 그래서 리스트는 초기화 해줄 때 마다 새로운 메모리에 데이터를 할당합니다.
x = [1, 2, 3]
# 함수를 이용한 리스트 복사
y = x.copy()
y.append(4)
# slicing을 이용한 리스트 복사
z = x[:]
z.append(5)
print(x) # [1, 2, 3, 4]
print(y) # [1, 2, 3]
print(z) # [1, 2, 3, 5]이미 존재하는 리스트를 별개의 객체로 복사하기 위해 Python에서는 위와 같이 2가지 방법을 제공하고 있습니다.
리스트 연산
w = [1, 2, 3]
print(id(w)) # 4528143040
x = [3, 4, 5]
print(id(x)) # 4528461952
y = w + x
print(y) # [1, 2, 3, 3, 4, 5]
print(id(y)) # 4528462016
z = y * 2
print(z) # [1, 2, 3, 3, 4, 5, 1, 2, 3, 3, 4, 5]
print(id(z)) # 4528143232리스트에서는 더하기와 곱셈 연산을 할 수 있습니다. 리스트에 연산을 하는 경우 기존 객체의 값을 수정하는 것이 아니라... 변경된 데이터를 새로운 객체를 메모리에 할당해서 리스트를 생성해줍니다.
immutable과 mutable
데이터 타입에 대한 글에서 숫자, 문자형 데이터는 변할 수 없는(immutable) 데이터라고 설명한 적 있습니다. 리스트의 경우 변할 수 있는(mutable) 데이터 입니다.
x = [1, 2, 3]
print(id(x)) # 4377230016
x.append(4)
print(id(x)) # 4377230016예제에서 볼 수 있듯이... 리스트에 4를 넣어줘서 데이터가 변했습니다. 그런데 객체의 주소는 그대로 똑같습니다. 이런게 mutable하다는 뜻 입니다. 이번에는 mutable한 리스트와 immutable한 문자형 데이터 타입을 비교해서 이해를 돕겠습니다.
# mutable한 list
x = [1, 2, 3]
print(id(x)) # 4425165504
x[-1] = 5
print(x) # [1, 2, 5]
print(id(x)) # 4425165504
# immutable한 문자형 타입
text = 'myjamong'
print(text[-1]) # g
text[-1] = 'a' # TypeError: 'str' object does not support item assignment예제에서 볼 수 있듯이 리스트에서 데이터를 변경했을 때 똑같은 객체 주소를 바라보고 데이터를 변경할 수 있는 것을 확인 했습니다. 이는 리스트 데이터 구조가 mutable하기 때문 입니다. 그런데 문자형 데이터인 text 변수는 타입 오류가 발생합니다. 문자형 데이터도 리스트처럼 인덱스를 이용해서 문자열의 일부 데이터를 읽을 수 있는데 수정하는 것은 안됩니다. 이는 문자형 데이터 타입은 immutable하기 때문입니다.
List의 다양성
x = [1, 2.5, '자몽', [1, 2, 3]]Python의 List는 타입에 대한 제한이 없습니다. Java난 C의 경우 하나의 배열에는 한 가지 타입의 데이터만 들어갈 수 있는데 Python에서는 모든 타입을 같이 들고 있는 리스트를 만들 수 있습니다. 위의 예시처럼 정수, 실수, 문자열, 리스트안에 리스트를 같이 리스트에 넣어서 사용할 수 있습니다.
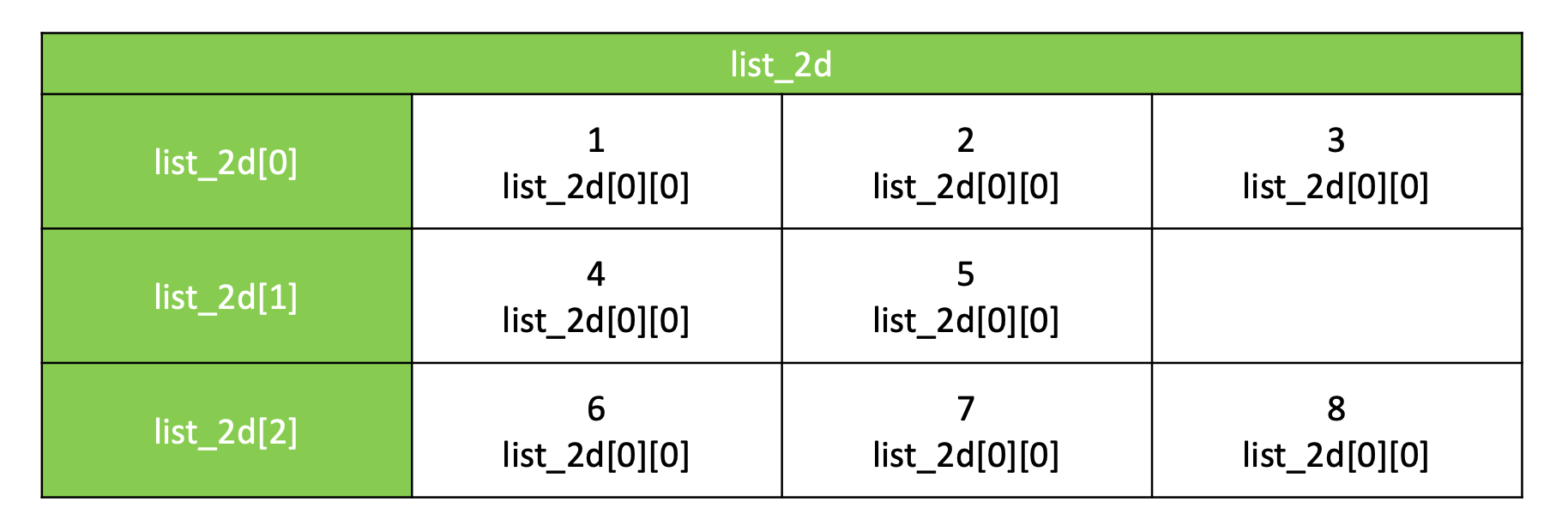
list_2d = [
[1, 2, 3],
[4, 5],
[7, 8, 9]
]배열안에 배열을 중첩해서 넣어서 2차 3차 배열 등 고차 배열을 만들어 사용할 수 있습니다.
list는 python으로 개발하면서 가장 많이 사용되는 데이터 구조가 될겁니다. 그만큼 중요하니 충분히 이해하고 넘어가는 것이 좋습니다.
x = []
print(x) # []
x = list() # []
print(x)빈 리스트를 생성해서 사용할 수 있습니다. 아직 어떤 데이터를 넣어야할지 정하지 않았을 때 빈 리스트를 생성해서 사용할 수 있습니다.
Tuple(튜플)
Tuple은 immutable한 list입니다. list와 똑같이 인덱스를 이용해서 읽을 수 있고 데이터가 순차적으로 되어 있는 데이터 구조입니다.
# 소괄호를 이용한 튜플 초기화
t = (1, 2, 3, 4, 5)
print(type(t)) # <class 'tuple'>
print(t) # (1, 2, 3, 4, 5)
# 괄호 없는 튜플 초기화
t = 1, 2, 3, 4, 5
print(type(t)) # <class 'tuple'>
print(t) # (1, 2, 3, 4, 5)리스트는 대괄호를 이용해서 선언했다면... 튜플을 소괄호를 이용하거나 괄호 없이 콤마를 이용해서 초기화할 수 있습니다. 리스트와는 다르게 immutable하기 때문에 append나 remove와 같이 데이터를 변경하는 함수를 사용할 수 없고 직접 인덱스에 접근해서 데이터를 수정할수도 없습니다.
그럼... 이런 튜플을 왜 사용하는 것 일까요? 왜 immutable한 list가 필요한 것 일까요?
Tuple을 사용하는 이유
import sys
import timeit
# list 생성 속도
start_time = timeit.default_timer()
l = [1, 2, 3, 4, 5]
print('list 생성 속도 : ', format(timeit.default_timer() - start_time, '.10f'))
# tuple 생성 속도 : 0.0000008920
# tuple 생성 속도
start_time = timeit.default_timer()
t = (1, 2, 3, 4, 5)
print('tuple 생성 속도 : ', format(timeit.default_timer() - start_time, '.10f'))
# tuple 생성 속도 : 0.0000005320
"""
list : 0.0000008920
tuple : 0.0000005320
--> tuple이 list보다 약 40% 빠르다.
"""
# list 데이터 접근 속도
start_time = timeit.default_timer()
print(l[1]) # 2
print('list 데이터 접근 속도 : ', format(timeit.default_timer() - start_time, '.10f'))
# list 데이터 접근 속도 : 0.0000039290
# tuple 데이터 접근 속도
start_time = timeit.default_timer()
print(t[1]) # 2
print('tuple 데이터 접근 속도 : ', format(timeit.default_timer() - start_time, '.10f'))
# tuple 데이터 접근 속도 : 0.0000029280
"""
list : 0.0000039290
tuple : 0.0000029280
--> tuple 이 list보다 약 25% 빠르다.
"""
# 사용하는 메모리 크기 비교
print('list의 메모리 크기 : ', sys.getsizeof(l)) # list의 메모리 크기 : 120
print('tuple의 메모리 크기 : ', sys.getsizeof(t)) # tuple의 메모리 크기 : 80
"""
list : 120
tuple : 80
--> tuple이 list 보다 약 33% 메모리 용량을 덜 차지한다.
"""성능의 차이가 있다는 것이 가장 큰 차이 입니다. list와는 다르게 tuple은 immutable하기 때문에 append나 remove처럼 데이터를 제어하는 메소드를 객체에서 갖고 있지 않습니다. 그러다보니 메모리에서는 상대적은 적은 공간을 차지하게 될 것이고 객체를 생성하거나 탐색할 때 더 적은 시간이 소요됩니다.
위 예시 에서는 sys와 timeit 모듈을 사용해서 list와 tuple의 생성 속도, 접근 속도 그리고 메모리 사용 크기를 비교 했습니다. 데이터의 양이 크지 않아 많은 차이는 없지만... tuple이 list 보다 더 빠르고 효율적으로 리소스를 활용하고 있는 것을 볼 수 있습니다. 큰 데이터를 다룰수록 차이는 점점 벌어질 것 입니다.
이런 이유로 순차적인 데이터를 변경할 필요가 없는 경우... list보다는 tuple을 사용하는 것을 고려해볼 수 있습니다.
tuple의 packing과 unpacking
tuple은 데이터가 변하지 않는 경우 사용되지만... 데이터 타입이 다른 경우에도 많이 사용되기도 합니다. 대표적인 예로 tuple의 packing과 unpacking을 이용할 때 다른 데이터 타입을 사용합니다.
# tuple packing
result = '수학', 100, '영어', 95.5
# tuple unpacking
math, m_score, english, e_score = result
# 함수의 반환값을 tuple packing
def report(x, y):
result = '불합격'
is_smart = False
if x + y > 90:
result = '합격'
is_smart = True
return result, is_smart, x + y
# 함수의 반환값을 tuple unpacking
pass_result, smart_bool, score = report(50, 45)
print(pass_result, smart_bool, score) # 합격 True 95packing : 튜플로 데이터를 묶어주는 것을 패킹이라고 힙니다. 즉 튜플로 데이터들을 할당해주는 것이 packing 입니다.
unpacking : 튜플의 데이터를 풀어서 각각 변수에 할당해주는 것이 unpacking입니다.
이런 tuple의 packing과 unpacking을 함수의 반환값을 처리할 때 가장 많이 사용합니다. 함수에 대한 내용은 이 후 글에서 자세히 다룰 것이고 지금은 "함수란 것이 있다" 정도로만 이해하면 될 것 같습니다. 위의 예제에서는 x, y를 기준으로 합격 불합격에 대한 결과와 똑똑한지의 여부와 합산 값을 반환해주는 함수(report)를 사용했습니다.
return할 때 3개의 값(result, is_smart, x + y)을 packing해주고 함수를 호출해서 3개의 값을 unpacking해서 3개의 변수에(pass_result, smart_result, score) 할당해줬습니다.
여러 모듈에 작성된 함수들이 이런식으로 tuple의 packing과 unpacking을 이용해서 값을 반환해주고 있습니다. 잘 활용하면 유용하게 사용될 수 있습니다.
tuple 사용 시 주의사항
# string type
t = 'jamong'
print(type(t)) # <class 'str'>
# tuple type
t = 'jamong',
print(type(t)) # <class 'tuple'>데이터가 하나만 들어 있는 튜플을 생성하고 소괄호를 이용하지 않는 경우 꼭 끝에 ','를 붙여줘야한다. 붙여주지 않으면 튜플이 아닌 다른 타입으로 인식할 수 있습니다.
# tuple내에 mutable한 타입의 데이터는 데이터 변경이 가능하다.
t = (100, 'text', ['apple', 'lemon'])
t[2][0] = 'grape'
print(t) # (100, 'text', ['grape', 'lemon'])
# tuple의 데이터는 immutable하기 때문에 변경이 불가능하다.
t[2] = ['watermelon'] # TypeError: 'tuple' object does not support item assignmentPython의 모든 것이 오브젝트로 되어 있는 특징이 있기 때문에... 위에 처럼 tuple내의 mutable한 데이터는 변경할 수 있다는 것을 암시적으로 알 수 있습니다. tuple의 값들이 각 객체기 때문에... 객체를 변경하는 것이 아니고 객체 내부의 값들을 변경하는 mutable한 데이터라면 변경이 가능하겠죠?
Set(세트)
세트는 순서가 없고 중복이 없는 데이터 집합입니다. 과일 가계에서 판매하고 있는 과일들의 종류를 알기 위해 사용한다던가... 회사에서 프로그래머들이 사용할 수 있는 프로그래밍 언어의 종류가 어떤것이 있는지 확인하는 등 중복을 없애고 존재하고 있는 데이터를 확인하기 위해 많이 사용됩니다.
fruits = {'apple', 'lemon', 'watermelon', 'apple'}
print(type(fruits)) # <class 'set'>
print(fruits) # {'lemon', 'watermelon', 'apple'} 순서가 없으므로 출력이 매번 변경됩니다.
# 빈 세트는 함수를 통해서만 생성할 수 있다.
d = {}
print(type(d)) # <class 'dict'>
s = set()
print(type(s)) # <class 'set'>
print(s) # set()세트는 중괄호를 이용해서 초기화할 수 있습니다. 하지만... 뒤에서 알아볼 dictionary 타입도 중괄호를 사용하기 때문에 빈 세트를 생성할 때는 set함수를 꼭 사용해야합니다. 위 예제에서 볼 수 있듯이 fruits 세트에서 중복을 제거하고 순서도 매번 실행할 때 마다 다른 값을 얻는 것을 확인할 수 있습니다.
Set 내장 함수 제어
set도 mutable 데이터 구조입니다. 값을 변경할 수 있습니다.
fruits = {'apple', 'lemon', 'watermelon', 'apple'}
print(fruits) # {'lemon', 'watermelon', 'apple'} 순서가 없으므로 출력이 매번 변경됩니다.
# 세트에 추가하기
fruits.add('melon')
print(fruits) # {'apple', 'melon', 'lemon', 'watermelon'}
# 세트에 모든 엘러멘트 추가하기
fruits.update(['grape', 'watermelon', 'mango'])
print(fruits) # {'melon', 'apple', 'lemon', 'mango', 'grape', 'watermelon'}
# 세트에서 제거하기(매개변수로 받은 값이 세트에 없으면 오류가 발생한다.)
fruits.remove('grape')
print(fruits) # {'apple', 'watermelon', 'lemon', 'mango', 'melon'}
# fruits.remove('grape') # KeyError: 'grape'
# 세트에서 제거하기(매개변수로 받은 값이 세트에 있으면 삭제한다. 오류가 발생하지 않는다.)
fruits.discard('watermelon')
print(fruits) # {'lemon', 'melon', 'mango', 'apple'}
fruits.discard('watermelon')
# 세트에서 무작위로 값을 반환하고 제거한다.
print(fruits.pop()) # 무작위로 값이 나오기 때문에 어떤 값이 나올지 모른다.
# 세트에서 모든 값을 제거한다.
fruits.clear()
print(fruits) # set()함수들은 실습을 통해 확인한다.
세트의 집합 연산
Python의 세트는 연산기호들을 통해서 집합에 대한 연산이 가능합니다.
fruits1 = {'apple', 'lemon', 'watermelon', 'apple'}
fruits2 = {'apple', 'lemon'}
fruits3 = {'apple', 'lemon'}
fruits4 = {'apple', 'grape'}
"""
비교 연산으로 크다 작다의 개념으로 이해하면 됩니다. subset
이하, 이상 --> 같은 경우를 포함
초과, 미만 --> 같은 경우는 미포함
"""
# fruits1이 fruits2의 상위집합인가?
print(fruits1 >= fruits2) # True
print(fruits1 > fruits2) # True
# fruits1이 fruits2의 부분집합인가?
print(fruits1 <= fruits2) # False
print(fruits1 < fruits2) # False
# fruits2가 fruits3의 상위 집합인가?
print(fruits2 >= fruits3) # True
# 같은 경우는 False
print(fruits2 > fruits3) # False
# 합집합
print(fruits2 | fruits4) # {'grape', 'lemon', 'apple'}
# 교집합
print(fruits2 & fruits4) # {'apple'}
# 차집합
print(fruits1 - fruits2) # {'watermelon'}
# 여집합
print(fruits1 ^ fruits4) # {'grape', 'watermelon', 'lemon'}실습을 통해 직접 확인해본다.
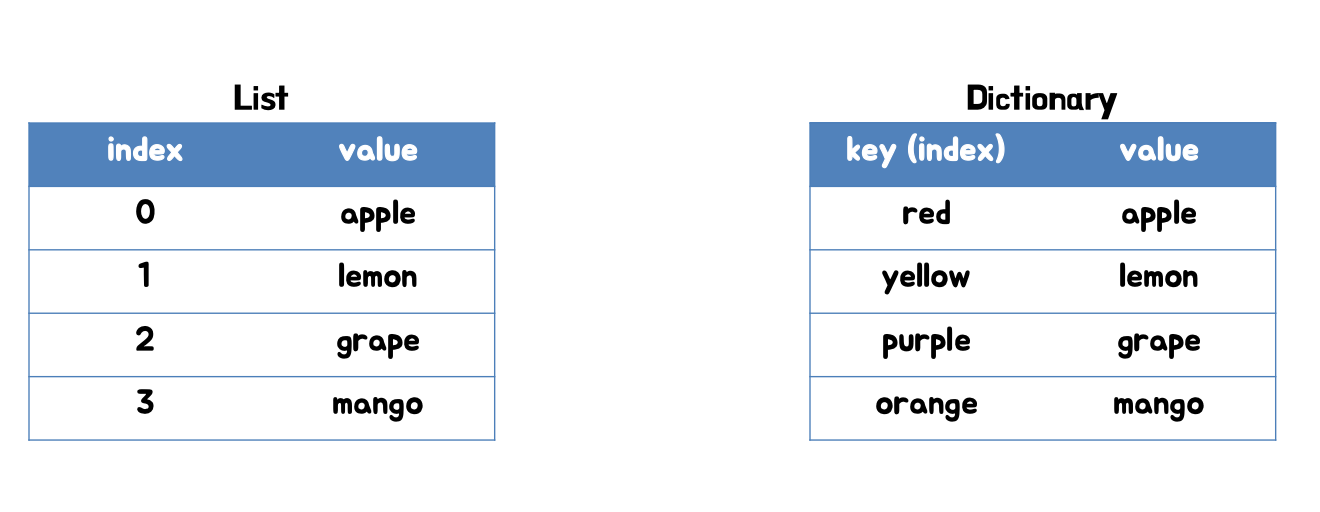
Dictionary(딕셔너리)
다른 언어에서의 Map이라는 오브젝트와 동일한 데이터 구조 입니다. key, value를 쌍으로 구성된 집합입니다. list나 tuple은 인덱스가 숫자의 형태로 되어 있는데 dictionary의 경우 인덱스를 문자형이나 숫자형처럼 immutable한 데이터 타입으로 되어 있습니다. 숫자보다는 문자형으로 key를 사용합니다.
d = {
'red': 'apple'
,'yellow': 'lemon'
,'purple': 'grape'
,'orange': 'mango'
}
print(type(d)) # <class 'dict'>중괄호를 이용해서 Dictionary를 선언해 줄 수 있고 세미콜론(:)를 기준으로 key:value 형태로 데이터를 저장할 수 있습니다.
Dictionary 읽기
d = {
'name': 'tom',
'age': 30,
'items': {
'pockets': 3,
'baskets': [
[
'grape',
'lemon'
],
[
'apple',
'watermelon'
]
]
},
1: 25
}
print(d['name']) # tom
print(d['items']['pockets']) # 3
print(d['items']['baskets'][1]) # ['apple', 'watermelon']
print(d[1]) # 25dictionary는 key의 값만 mutable한 데이터 타입으로 지정해주면 됩니다. value로는 숫자형, 문자형과 같은 데이터 타입이나 list, set과 같은 데이터 구조가 들어갈수도 있습니다. dictionary의 key가 index의 역할을 해주기 때문에 list를 읽었던 방법처럼 대괄호를 이용해서 접근할 수 있습니다.
Dictionary 생성 예제
a = {'name': 'jamong', 'age': 30}
b = dict(name='jamong', age=30)
c = dict(zip(['name', 'age'], ['jamong', 30]))
d = dict([('name', 'jamong'), ('age', 30)])
e = dict({'age': 30}, name='jamong')
print(a == b == c == d == e) # Truedict 함수를 이용해서 여러 방법으로 dictionary를 생성할 수 있습니다.
Dictionary 데이터 제어
d = {'name': 'tom'}
# dictionary 데이터 추가
d['age'] = 30 # {'name': 'tom', 'age': 30}
print(d)
# dictionary 데이터 삭제
del d['name']
print(d) # {'age': 30}dictionary의 key값을 이용해서 직접 데이터를 추가할 수 있습니다.
del 키워드를 사용해서 dictionary 값을 삭제할 수 있습니다.
Dictionary 함수를 통한 데이터 제어
d = {
'name': 'tom',
'age': 30
}
# dictionary에 key의 존재여부 확인
print('name' in d) # True
print('name' not in d) # False
# dictionary (key, value) 형식으로 데이터 추출
print(d.items()) # dict_items([('name', 'tom'), ('age', 30)])
# dictionary key 값들을 추출한다.
print(d.keys()) # dict_keys(['name', 'age'])
# dictionary value 값드을 추출한다.
print(d.values()) # dict_values(['tom', 30])
# dictionary의 value를 key값으로부터 얻을 수 있다.
# key가 없는 경우 default로 None을 반환하고 2번째 인자를 지정해주면 해당 값을 반환한다.
print(d.get('name')) # tome
print(d.get('height')) # None
print(d.get('height', 123)) # 123
# dictionary의 데이터를 수정한다.
# 이미 존재하는 key이면 overwrite하고 없으면 추가한다.
d.update({'age': 20})
print(d) # {'name': 'tom', 'age': 20}
# key에 해당하는 값을 반환하고 dictionary에서 삭제한다.
# key가 없으면 오류를 발생시킨다.
# 2번째 인가자 지정되어 있으면 오류가 아닌 해당 값을 반환한다.
# popitem 함수는 같은 기능이지만 값이 아닌 key:value 아이템을 반환한다.
print(d.pop('age')) # 20
print(d) # {'name': 'tom'}
print(d.pop('age')) # KeyError: 'age'
print(d.pop('age', 123)) # 123
# dictionary 데이터 모두 삭제
d.clear()
print(d) # {}예제를 통해 확인한다.
dictionary vs list
list는 숫자형태로 인덱스가 부여되고 dictionary는 key 형태의 인덱스를 직접 설정해줍니다. dictionary의 경우 문자형태 뿐만 아니라 숫자형태로도 key를 지정해줄 수 있는데... 그럼 key값을 숫자형태로 사용한다면 어떤 데이터 구조를 사용해야할까요?
우선 성능적으로 봤을 때 데이터에 접근하는 속도는 dictionary보다는 list가 훨씬 빠릅니다. 사용하는 데이터가 순차적인 번호로 인덱싱되어서 사용할 수 있다면 list나 tuple을 사용하는 것을 권장드립니다.
정리
- 데이터 구조는 여러 데이터를 효율적으로 저장하기 위한 데이터 집합
- List는 데이터를 순차적으로 저장하고 mutable한 데이터 구조
- python에서는 음수 인덱스 사용 가능
- slicing 기능을 이용해서 편리하게 범위 데이터를 읽을 수 있다
- 변수에 같은 데이터가 들어 있는 list를 할당해도 다른 주소를 참조
- Tuple은 immutable한 List
- Tuple의 성능이 list보다 효율적이기 때문에 데이터의 변경이 필요없다면 Tuple을 사용할 것
- Tuple의 packing, unpacking을 사용하면 편리함
- Set는 순서가 없고 데이터 중복이 없는 데이터 집합
- Set를 이용해서 데이터 집합 연산 가능
- Dictionary는 문자나 숫자형 데이터 타입을 index로 하는 key, value 쌍으로 구성된 집합
- 데이터 접근 속도는 dictionary보다 list가 더 빠르기 때문에 순차적인 번호의 인덱스를 사용한다면 list를 사용할 것



댓글