SQL Loader

비오라클 데이터베이스에서 오라클 데이터베이스로 데이터를 이동하는 방법으로 SQL Loader를 사용할 수 있습니다. SQL Loader는 csv나 tsv 파일처럼 특정 구분자나 위치로 정의되어 있는 텍스트파일 형식의 데이터를 이용해서 import하는 방식입니다. SQL Loader를 사용하기 위해서는 이러한 데이터가 담겨져 있는 데이터 파일과 import하는 데이터 파일 및 테이블에 대한 정보가 기술되어져 있는 컨트롤 파일 두가지를 이용합니다.
SQL Loader 실습
실습환경
OS : Red Hat Enterprise Linux Server release 6.10
DB : Oracle 11.2.0.1
SID : orcl
host : 601d2fce71dc
실습목표
- import용 Data file을 각 형식별로 생성
- import용 Control File 형식별 옵션별 생성
- orcl hr.departments 테이블의 데이터를 hr.dept_loader 테이블로 복제
Import용 Data file
[oracle@601d2fce71dc ~]$ sqlplus hr/hrHR 계정으로 접속해서 데이터파일은 구분자를 이용한 칼럼의 구분과 위치로 구분한 데이터파일 2가지를 이용해서 실습 진행하겠습니다.
Comma Seperated
HR@orcl>
select
department_id
|| ',' ||
department_name
|| ',' ||
manager_id
|| ',' ||
location_id
from departments;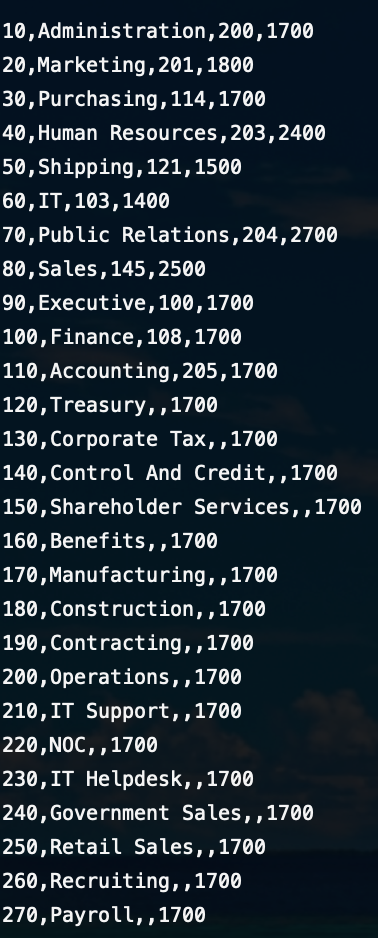
Comma 단위로 구분값을 갖는 데이터 생성했습니다.
Position
HR@orcl>
select
rpad(department_id,5)
|| rpad(department_name,31)
|| rpad(manager_id,7)
|| location_id
from departments;
위치로 구분한 데이터 파일을 생성했습니다.
column1 (1:4)
column2 (6:35)
column3 (37:42)
column4 (44:47)
Oracle에서 제공하는 연결 연산자를 이용해서 각 형식별로 Import용 데이터 파일안에 넣을 데이터를 만들었습니다. 해당 쿼리 결과를 복사해서 Import용 데이터파일을 만들예정입니다. 데이터의 양이 많은 경우 spool 명령어를 사용해서 바로 파일을 만드는 작업을 해도 됩니다.
[oracle@601d2fce71dc ~]$ vi /opt/oracle/departments.dat복사한 내용을 파일에 저장합니다.
Import Control File
[oracle@601d2fce71dc ~]$ vi /opt/oracle/department.ctl
append(Comma Seperated)
load data
infile '/opt/oracle/departments.dat'
append
into table hr.dept_loader
fields terminated by ','
(
department_id
,department_name
,manager_id
,localtion_id
)append 옵션을 사용하면 기존에 있는 테이블의 데이터에서 추가적으로 insert하는 작업을 합니다.
infile - 데이터 파일의 위치
into table - table 오브젝트의 이름
fields terminated by - 구분자
truncate(Comma Seperated)
load data
infile '/opt/oracle/departments.dat'
truncate
into table hr.dept_loader
fields terminated by ','
(
department_id
,department_name
,manager_id
,localtion_id
)truncate 옵션을 사용하면 기존에 있는 데이터를 지우고 Import하는 데이터만 반영합니다.
position datafile import
load data
infile '/opt/oracle/departments.dat'
append
into table hr.dept_loader
(
department_id position(1:4)
,department_name position(6:35)
,manager_id position(37:42)
,location_id position(44:47)
)위치기반으로 Import할 수 있습니다.
Import
HR@orcl> create table dept_loader as select * from departments where 1=0;SQL Loader를 사용할때는 미리 테이블을 생성해야 Import가 가능합니다.
[oracle@601d2fce71dc ~]$ sqlldr hr/hr control=/opt/oracle/departments.ctl
27개의 행이 성공적으로 Import된것을 확인할 수 있습니다. 각 Control File 옵션에 따라 데이터의 import 상태를 이후 확인하면 됩니다.
Direct Option
[oracle@601d2fce71dc ~]$ sqlldr hr/hr control=/opt/oracle/departments.ctl direct=true[oracle@601d2fce71dc ~]$ vi departments.log 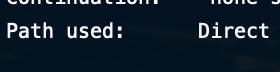
Direct Option을 사용하고 로그를 확인해보면 Path used 값이 Conventional이 아닌 Direct로되어 있는 것을 확인할 수 있습니다. Direct 옵션을 사용하면 빠르게 Import 작업을 진행할 수 있습니다. 기존 Conventional한 방식은 Import하는 과정에서 SGA 메모리를 사용하게됩니다. 운영중인 데이터베이스에서 공유되는 메로리로 Import작업을 하게되면 경합이 발생하여 Waiting Event가 발생할 수 있고 공유되는 공간이다보니 작업이 Direct한 방식보다 상대적으로 느립니다. Direct한 방식은 PGA영역을 사용해서 datafile에 바로 Insert할 수 있는 방식으로 SGA 공유메모리를 사용하지 않습니다.
Import 이후
Import가 완료되면 작업 도중 세부적으로 어떤 일이 발생했는지 기록되는 log파일이하나 생성됩니다. Import가 성공할수도 있지만 데이터 파일의 문제로 실패할수도 있습니다. 실패시 Discard File과 Bad File 두가지 로그파일이 생성될 수 있습니다.
Discard File
Control File안에 조건을 만족시키지 못한 행들이 기록됩니다.
Bad File
Insert 하고자하는 테이블에 일치하지 않는 데이터가 Import되는 경우 문제가 있었던 행들이 기록됩니다.




댓글