List Partition Table
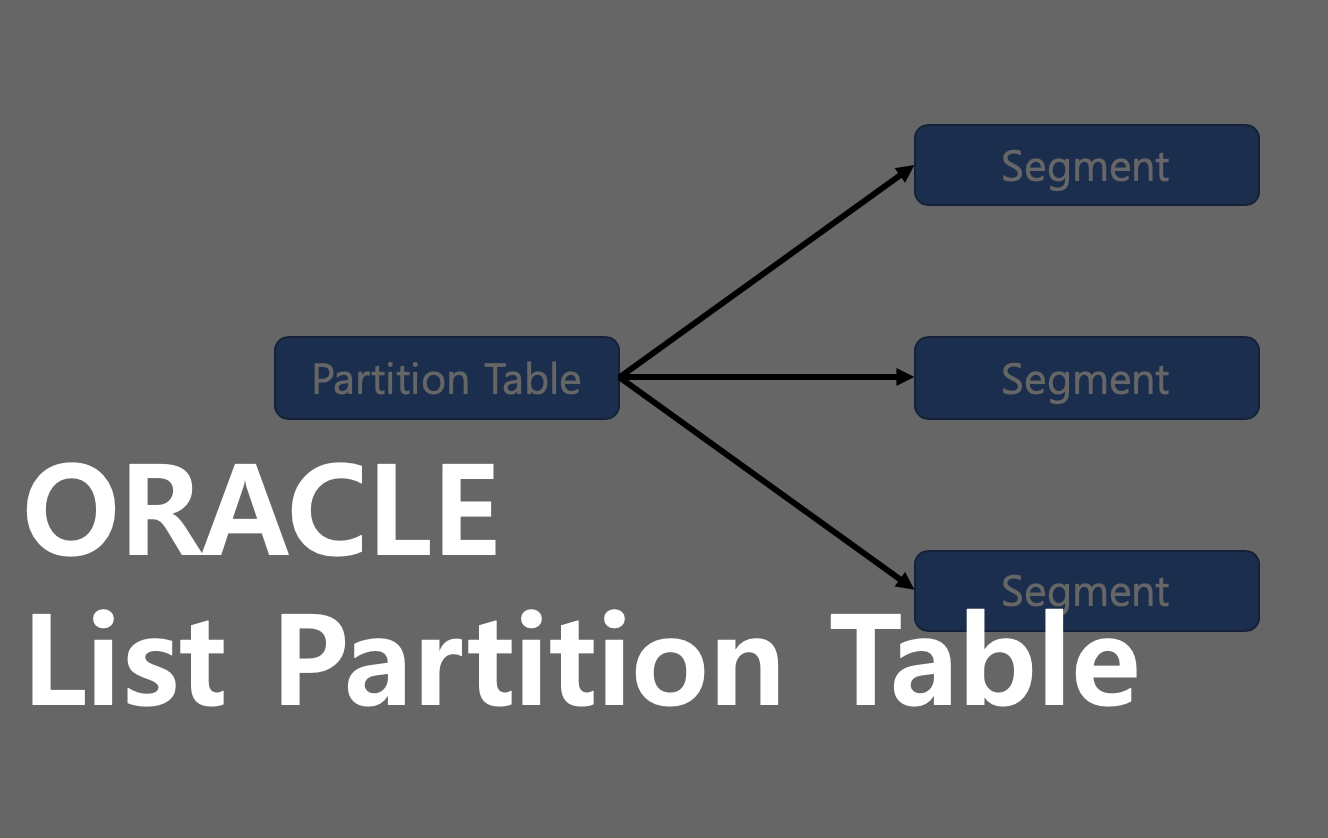
Object라는 것은 유저가 생성할 수 있는 것입니다. Segment는 Object들 중에서 데이터를 저장하기 위해서 저장공간이 필요로하는 것입니다. 기본 테이블은 하나의 Segment를 갖는 것을 원칙으로 해서 데이터의 양이 많이질 수록 쿼리작업을하는데 시간이 오래걸리게 됩니다. 만약 하나의 테이블이더라도 특정 기준으로 여러 Segment를 만들어서 필요한 데이터 범위에서만 조회를 한다면 어떨까요? 예를 들어 2015년도의 전체 데이터를 찾고싶은데 Table에는 1990년부터 데이터가 존재합니다. 여러 행을 결과로 반환하기 때문에 Full Table Scan 작업을 하게될텐데 1990년도 부터 모두 탐색하면 시간이 정말 오래 걸릴겁니다. 이럴때 기간을 기준으로 Partition을 잡아서 Segment를 나누면 2015년도로 만들어진 Segment를 찾아 탐색하여 훨씬 빠른 속도로 검색이 가능할겁니다.
Partition Table은 데이터가 늘어나면서 관리하기 편하게 하기 위한 목적으로 만들어졌습니다. 그런데 사용하다보니 성능도 좋아지게되어 자주 사용합니다. Partition Table은 주로 오랜 기간 쌓아온 데이터를 기간 범위로 잡고 현장에서는 90%이상 정보다 Range Partition Table을 사용합니다. Range Partition을 다루기 전에 특정 칼럼의 값으로 Partition 작업을 하는 List Partition Table을 이용해보겠습니다.
List Partition Table 실습
실습환경
OS : Red Hat Enterprise Linux Server release 6.10
DB : Oracle 11.2.0.1
SID : orcl
host : 601d2fce71dc
user : scott
Partition Table 생성
SCOTT@orcl>
create table dept_test
(
deptno number
,dname varchar2(20)
)
partition by list(deptno)
(
partition dept_10 values(10)
,partition dept_20 values(20)
,partition dept_30 values(30)
,partition dept_40 values(40)
);dept_test라는 테이블을 생성하고 deptno 값을 기준으로 4개의 segment 저장공간을 만들었습니다.
SCOTT@orcl>
select
table_name
,partitioning_type
,partition_count
,status
from user_part_tables;
SCOTT@orcl>
select
table_name
,partition_name
,high_value
from user_tab_partitions;
여러 뷰들을 이용해서 생성한 Partition의 정보를 확인할 수 있습니다.
Data Insert
SCOTT@orcl> insert into dept_test select deptno, dname from dept;데이터를 조회하기 이전에 data를 insert 하겠습니다.
Data Select
SCOTT@orcl> select * from dept_test;
먼저 전체 데이터를 조회해봤습니다.
SCOTT@orcl> set autot trace explain
SCOTT@orcl> select * from dept_test;
실행 계획만 확인하기 위해 autotrace를 이용했습니다. Table Full Scan 작업을 통해 데이터를 읽어오는 것을 확인할 수 있는데 Partition List 전체를 확인하는 것을 볼 수 있습니다.
SCOTT@orcl> set autot off
SCOTT@orcl> select * from dept_test partition(dept_10);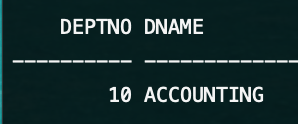
이번에는 해당 Partition의 내용만 조회하기 위한 쿼리를 작성했습니다. partition의 이름을 갖고 부서 번호가 10인 partition의 데이터만 읽었습니다.
SCOTT@orcl> set autot trace explain
SCOTT@orcl> select * from dept_test partition(dept_10);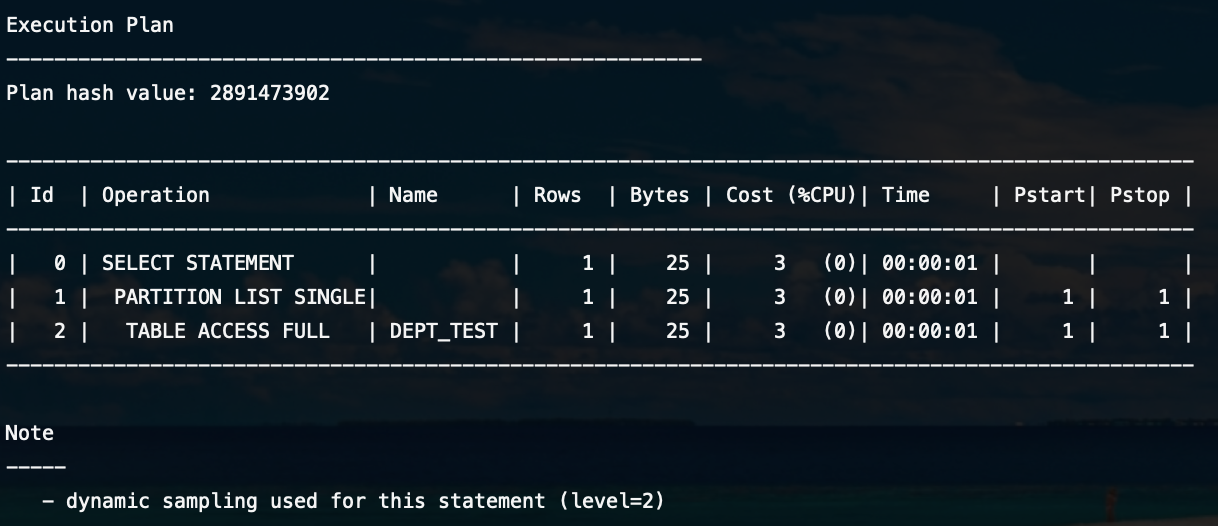
실행계획을 확인해보니 이번에는 Full Table Scan 작업을 SINGILE Partition에서 조회하는 것을 확인했습니다.
대부분의 Partition Table은 Range방식을 사용합니다. 그러면 위에서 작업한 List Partition Table은 언제 사용될까요? 주로 데이터가 정말 많고 SQL WHERE절에서 많이 사용되고 균등하게 데이터가 분포되어 있을 때 사용합니다. 또하나의 장점으로 연관되지 않는 데이터를 그루핑 할 수 있는 장점이 있습니다.
create table dept_test
(
deptno number
,dname varchar2(20)
)
partition by list(deptno)
(
partition dept_30_under values(10,20,30)
,partition dept_40_upper values(40,50,60,70)
);위와 같이 partition list의 values 값을 여러개 나열하여 상관이 없는 데이터 끼리 묶어 관리할 수 있습니다.




댓글